用生成的数据集训练未来几代机器学习模型可能会导致“模型崩溃”。

Epoch AI:2028年互联网上所有高质量文本数据将被使用完毕
多知8月2日消息,据研究公司Epoch AI预测,人类生成的公开文本数据的总有效存量约为300万亿tokens。至2028年,互联网上的所有高质量文本数据或将被悉数使用完毕,而机器学习所依赖的高质量语言数据集,其枯竭的时间点甚至可能提前至2026年。
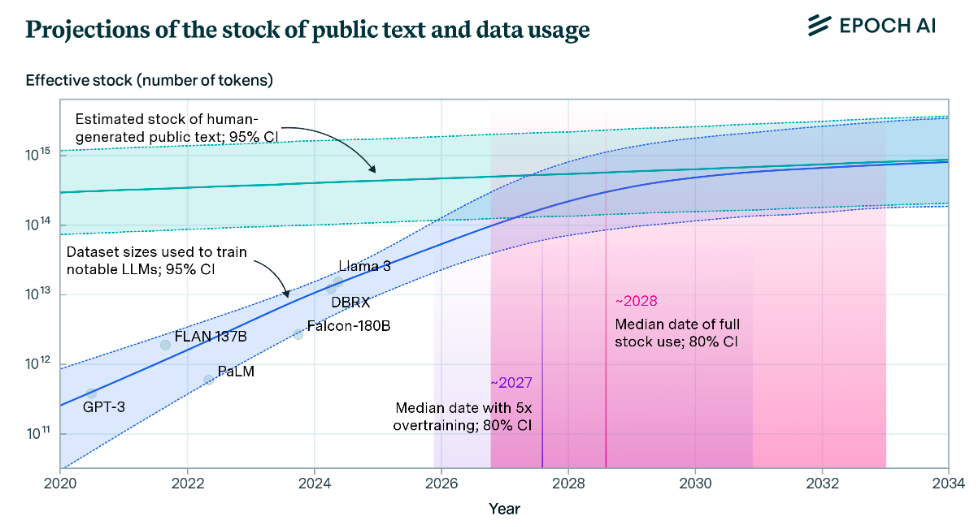
为了在 2028 年之后保持当前的进展速度,开发或改进替代数据源(如合成数据)似乎至关重要。尽管挑战仍然存在,但这些挑战可以使机器学习继续扩展到公共文本之外。不过,研究人员指出,用生成的数据集训练未来几代机器学习模型可能会导致“模型崩溃”。
不过,也有观点认为,在语言模型的细分领域内,仍有一片未被充分探索的数据蓝海,蕴藏着丰富的差异化信息,等待着被挖掘利用。