解决教育场景大模型幻觉的一种新思路。
解题出海产品竞争红海化,TutorEva凭什么收获200万用户?
来源|多知
作者|徐晶晶
2023年5月,一款名为“TutorEva”的AI解题产品登陆北美市场。
与字节Gauth、作业帮Question AI、Answer AI等面向泛学生群体的解题类出海产品均不同的是,TutorEva面向北美大学生提供多模态解题功能。体现在交互上,TutorEva的AI老师,可以边讲解、边板书画图,引导学生一步步思考。
截至目前,TutorEva已有200多万用户,预计ARR(Annual Recurring Revenue)超过百万美金。
TutorEva的背后是一家名为“悉之智能”(以下简称“悉之”)的教育科技公司。
不过,这并不是一家新公司。早在2017年,悉之便已成立,主攻“自动解题/讲题”,与头部教育公司开展了To B合作。2022,其开始寻求转型,探索“自动解题/讲题”出海的可能。
近两年,悉之在开源大模型的基础上深入一步:自研了KAS(Knowledge Agent)架构,训练了千亿基座模型EVA-LLM。当下,除了深耕海外市场外,悉之也将以To B模式拓展国内教育市场。
不过,显而易见的挑战是,国内的通用大模型、教育垂直大模型林立,悉之在教育生态位上的机会又在哪?
借助自研的KAS架构,其表示能让大模型的数学推理能力和准确性获得显著提升。如此来看,它更像是教育AI产品背后的大模型解决方案提供商。
实际上,在很多教育产品背后,已然有悉之的身影。例如,其与新东方优编程、希沃、紫光摩度均达成了合作。
和大多数To B的科技公司一样,悉之一贯低调,不过,其创始人孙一乔却并不欠缺一个典型的“95后”技术派该有的自信。目前,其团队接近80人,核心团队均来自清华北大。
近日,孙一乔向多知分享了他在当下阶段的思考:关于AI老师、关于教育解题产品的出海前景、关于教育垂直大模型、关于通用大模型的教育场景落地、关于GPT-4o的讲题功能……
01
解决教育场景大模型幻觉的一种新思路:“在推理层基于联合模型做输出”
“今年开始,我们明显感觉到,国内公司对AI教育的热情高涨。光是来这间办公室找我们谈合作的上市公司高管、行业大咖就有好几位。”
春江水暖。
在AIGC热潮下,作为一家以To B业务起家的公司,孙一乔显然比周围人更早感知到了今年非比寻常的一些变化。这给悉之带来的直接影响是,团队将今年的工作重心由此前的To C产品的出海转至To B解决方案业务。
当前,除了与新东方优编程合作研发“优香农大模型”外,悉之智能还与紫光摩度、希沃均达成了合作,共研大模型及应用层的AI老师产品。
这也不免让人好奇,这家公司究竟有什么样的核心竞争力?
故事要从一个青年的坚持讲起。
2017年,孙一乔从清华大学电子工程系毕业,跃入教育创业潮:他一直梦想着实现AGI。而要实现AGI,最重要的基石便是AI的数学能力及其背后的逻辑能力。
“要解决AI的数学能力,就要为AI提升数学能力这件事找到一个有价值的场景,这个场景必定是教育。”孙一乔笃定。
如何让AI提升数学能力?
起初,团队基于BERT架构结合KAS系统模型研究自动解题。当这波大模型热潮出现后,悉之在底层技术方面进行了迭代,引入了大模型。但是,大模型仍面临幻觉和逻辑推理等问题,在容错率极低的教育场景下,只有解决大模型幻觉和逻辑推理问题,才能解决AI的解题能力。当前,解决大模型幻觉问题常用的方式是RAG(Retrieval-augmented Generation,检索增强生成),但是悉之另辟思路,“在推理层基于联合模型做输出”。可以简单理解为,给了飞行员一本“操作手册”。
孙一乔举了个例子:
“如果现在让你坐飞船去月球,但驾驶员是GPT-4,你肯定不敢坐,因为大模型的幻觉避免不了。
但是,假设GPT-4在做任何操作前,都有一本完整的飞行员操作手册指引,这种情况下,你是不是就放心多了?
基于这本手册,GPT-4要做的只是规划和调度‘去月球走哪条路最快’,但无论走哪条路,都已经有写好的算法等待启用,这就会大大提高GPT-4带你去月球的可靠性。”
悉之要做的事,就是为大模型找到这本飞行员“操作手册”,降低其幻觉的产生。
孙一乔认为,纯粹的统计模型无法很好地解决数学题。而他的思路是,基于数学构建一套完整的知识体系,让AI在解数学题时能调用这些数学知识解题,以提升大模型的准确性。
在具体的技术路径上,悉之自研了KAS架构。
孙一乔自信地说:“我们认为类KAS架构正在成为主流,而且这个架构一定是最终的架构。”

悉之要做的是,“在推理层基于联合模型做输出”,“由一个大模型把题目拆解调度,在解决具体问题的时候,调用数学模型输出,比如有逻辑的推理、数学的推演,整个过程叫联合推理。”
孙一乔认为,RAG只是在大模型的输入中增加了prompt,本质上不改变大模型的能力。而KAS架构作用在大模型的推理和训练过程。一方面通过SFT和强化学习,教会大模型用工具调用的方式使用相关数学知识和解题技巧,另一方面,在模型的推理过程中,对它的求解结果进行推理、计算等的校验和修正。
也就是说,在KAS架构的帮助下,大模型增加了推理逻辑能力,让大模型“知其然,更知其所以然”。
如果KAS架构成为主流架构,是否意味着任何科技公司都可以探索这一方向?悉之的价值又在哪里?
孙一乔表示,KAS架构的实现,颇有门槛。“如果说,Transformer架构的门槛在于需要海量的数据。那我们这套架构的难点在于开发量是线性的,是一个耗时耗力的浩大工程,相当于把人类的所有的数学知识都要用AI能够编译的方式标注出来,还要用数据教会AI怎么使用它。”
02
“我们绝不做Chatbot”:一位擅长多模态讲题的AI老师是如何诞生的?
循着上述技术路线,从2021年开始,悉之花了近两年时间研发了这一架构。
在应用层,TutorEva也随之诞生。
相比GPT-4来说,TutorEva依托的高等教育模型有怎样的提升呢?孙一乔透露:“我们内部测试过,如果是微积分题,GPT-4的解题率不到70%。但是通过我们的模型做了提升和优化后,GPT-4的解题率可以提升到80%左右。”
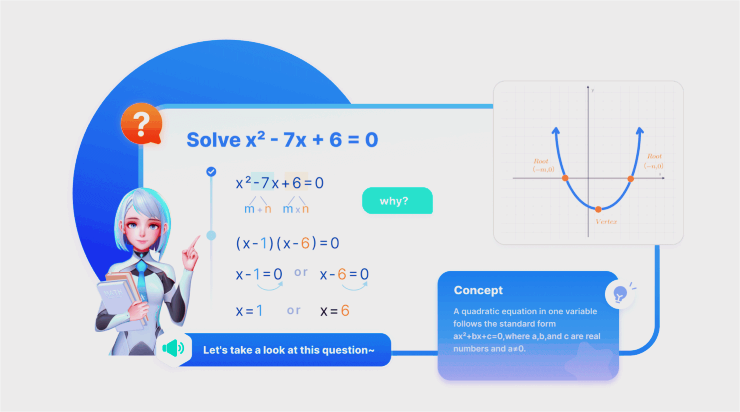
当解数学题时,通用大模型的做法只是像写小作文一样不断输出结果。但TutorEva不同,内置AI老师,会先给解题思路,然后边讲解、边板书画图,一步步引导学生思考。
虽然可能最后输出的答案都是相同的,但孙一乔解析了这两种输出方式背后的底层不同:
“其他公司使用通用大模型讲题的方法往往是把参考答案作为Prompt喂给大模型,让它讲,这样出错率很高。因为大模型的推理过程是不可解释的。
而我们不同,在解题过程中,将解题任务拆分为题意理解、预设思路、运用知识、逻辑推理、计算等子任务,调用不同的Agent执行。本质上是AI老师知道要用什么方法,再讲什么方法。大家总说大模型是不可解释的,我们首先让大模型的解题变得可解释,后面再加讲解。这才是顺理成章的。”
基于此,孙一乔认为,市面上很多AI老师不过是Chatbot(聊天机器人),但TutorEva并不是。“我们绝不做Chatbot。AI带来的最大的价值是AI老师可以对每个孩子都进行实时互动讲题。未来AI老师若要在很大程度上替代部分真人老师,那AI老师就一定不能只是聊天机器人。”
据孙一乔透露,TutorEva的AI讲解平均每道题的听讲时间超过3分钟。
截至目前,TutorEva有200多万用户,单月MRR(Monthly Recurring Revenue)超过10万美金,预计ARR(Annual Recurring Revenue)超过百万美金,续费率60%,讲解好评率84%。
孙一乔透露,接下来,TutorEva会聚焦在三个方向:
其一,继续优化模型能力。“我们很清楚,这个场景对AGI有巨大的帮助,所以我们要做一件模型层有壁垒的事儿,避免比如GPT新版本一出、创业公司死一堆的情况。”
其二,要构建一个生态。“现在做AI应用的公司,一定要实现大模型、场景、收入、数据飞轮的闭环。如果只是调个OpenAI接口,那肯定长久不了。如果你构造的是一个完整生态,大模型公司对你也有需求,你也能持续地为大模型公司产生场景、创造价值。”
其三,场景深耕,继续聚焦北美大学生,开发更多垂直功能。
悉之智能最近一次大范围走入人们的视野,是在今年5月底,和新东方优编程联合推出信息学领域首个垂直大模型——“优香农大模型”。信息学AI老师“悉加加”也依然采取互动式多模态讲题方式。
在孙一乔看来,“优香农大模型”带来了信息学领域师资供给侧改革的可能性。
03
“解题出海产品竞争红海化”,“教育生态细分且复杂,单纯的大模型公司无暇入场”
孙一乔判断,就海外的To C解题市场而言,当下已然处于红海竞争阶段,没有新入局的创业者的机会了。
“凡是基于大模型接口做应用的AI教育创业公司,都没有壁垒,这也意味着这是一个完全竞争市场,利润为零。
调接口做应用就是一个资本游戏,看谁能融到更多的钱,看谁能持续烧钱获客直至最后跑出来。
但这个时代已经没有这样的资本环境了,现在投放这么激烈,VC们早不相信这种套壳应用能够通过烧钱打品牌。
除非你做的事有一些壁垒,比如你的课程体系、模型、管理能力等,或者一些真正能解决技术难题的公司,或者对AGI有追求的大模型公司在这方面布局是有机会的。
但在当下,对新创业者挑战也很大。我们公司如果没有过去四五年的积淀,从头开始再做这件事,可能需要几千万美金。
如今,谁又能靠做AI教育垂直产品就融到几千万美金呢?”
尽管否定了新创业者的机会,但是,孙一乔认为,大厂生态下仍然有机会。“由于是有战略意义的,大厂一定要把解题场景占住。”
“在AI老师这个领域,如果GPT-4o讲题的场景真的能落地,基本上就赢了。但这条路其实还蛮漫长的,要达到理想状态,大概需要一两年。”
今年以来,孙一乔将视角切回到国内。
他认为,“如果在国内市场只提供解题功能,那还不如以小猿搜题为代表的这类工具产品。小猿们多年来已经通过人工题库的方式做到了解题的90%,国内大模型的解题能力在两年之内,不可能超过这些解题工具,起码从成本侧、性能侧来看,大模型还不足以和小猿们形成代际差。”
因此,在国内市场,悉之坚持做To B,“选择每个领域最头部的伙伴深度战略绑定”。“我们要做(就要做)这个生态位上最好的公司。”孙一乔说。
在国内,悉之基于开源模型,训练了千亿基座模型EVA-LLM。对比开源基座模型,悉之训练的模型在数学解题方面可以提升15%-25%的表现。
当前,一些通用大模型公司希望在教育场景落地,也在向教育领域拓展商业化场景。
不过,孙一乔认为,“国内教育生态复杂且细分,单纯的通用大模型公司无暇入场,它们应该聚焦AGI实现,不应该、也没有这个基因做教育。”
他提到,现在通用大模型公司的能力和教育公司真正的需求相差甚远。“而我们这类公司(作为桥梁)能很好地综合这两点。基于大模型公司的基座大模型,在教育环境下开发出针对性的算法和功能。”
创业七年,兜兜转转。
悉之有过一些成绩,也有一些压力:
“现在的大模型公司纯粹做模型和基础应用就行,教育公司纯粹做教育服务就行,而我们需要把全链条都做了。
我们要自训模型,需要大量的算力,它需要很大参数的基座模型。我们还要基于这个基座模型,自训我们的模型,也需要大量算力,所以我们的科研投入是很大的。科研投入完,我们还要给客户交付完整的产品方案。
但是目前的大环境要支持我们做全链条这件事有一定的难度。就现在的资本环境来说,除了大模型公司有很高的溢价外,并没有给到我们这类公司很高的溢价,这让我觉得我们的价值跟做的全链条事情有一点被低估。
这导致我们在资源上有点紧张,所以我们也在寻求跟一些大模型公司合作,由他们来提供算力,我们给他们提供一些价值,彼此合作。”
2023年9月的一场直播上,谈及值得投资人付出耐心的项目时,启明创投副总裁李定政回忆起2021年那次“坚定地”下注:
“当时(指2021年上半年)所有人都猜到教育新政策马上就要来了,也都预感到这次政策将会产生很大影响,但我们还是坚持在这样的环境下投了一家教育领域的AI创新公司。
它不仅能把一道微积分难度的数学题,解出答案,还能给到分步的交互式讲解。讲的过程中还会加入解题技巧、引用定理、类似题型处理等。
这是一个完整的师生交互的过程。这意味着每个人都可以拥有一位擅长个性化教学的AI老师。而这套过程要用真人老师来解决的话,成本通常是每小时200-400块钱。但是用AI解决,它的成本可能是几块钱的算力,对应的产品价格如果定在10块钱,对一些家庭来说,或许无法支付每小时200-400块钱,但肯定能付得起每小时10块钱。
这其实就是我们风险投资机构最应该去赌的东西。”
李定政口中的这家公司便是悉之。
直到今天,我们依然无法判断启明创投的这笔投资是赚是赔,但在这个年轻的团队身上,能看到新一代创业者用科技改变教育的努力。



