依托于豆包基座大模型和豆包大模型语音组的语音理解能力,同时具备了从外部获取知识的能力。
字节跳动推出大模型同传智能体,“接近人类同声传译水平”
多知7月30日消息,近日,字节跳动 ByteDance Research 团队的研究人员推出了端到端同声传译智能体:CLASI(Cross Language Agent - Simultaneous Interpretation) ,效果已接近专业人工水平的同声传译。
此前,市面上传统的同声传译软件通常采用级联模型(cascaded model)的方法,即先进行自动语音识别(Automatic Speech Recognition, ASR),然后再进行机器翻译(Machine Translation, MT)。这种方法存在一个显著的问题——错误传播。ASR 过程中的错误会直接影响到后续的翻译质量,导致严重的误差累积。此外,传统的同声传译系统由于受限于低延时的要求,通常只使用了性能较差的小模型,这在应对复杂多变的实际应用场景时存在瓶颈。
而CLASI 采用了端到端的架构,规避了级联模型中错误传播的问题,依托于豆包基座大模型和豆包大模型语音组的语音理解能力,同时具备了从外部获取知识的能力。从字节方面释出的几则视频中可以看到,无论是绕口令、文言文,还是充满即兴和灵感的随意聊天,模型都能流畅自然地给出准确的翻译结果。
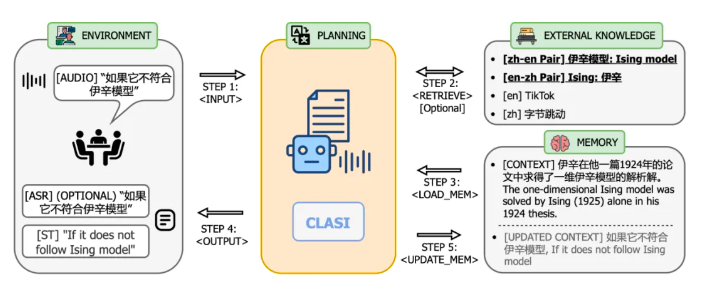
系统架构上,CLASI 采用了基于 LLM 智能体的架构,将同声传译定义为一系列简单且协调的操作,包括读入音频流,检索(可选),读取记忆体,更新记忆体,输出等。整个流程由大语言模型自主控制,从而在实时性和翻译质量之间达到了高效的平衡。该系统能够根据实际需求灵活调整各个环节的处理策略,确保在高效传递信息的同时,保持翻译内容的准确性和连贯性。CLASI 底层模型是一个 Encoder-conditioned LLM,在海量的无监督和有监督数据上进行了预训练。