长远来看,机器人一定会走进千家万户。

腾讯首席科学家张正友:仅把大模型塞进机器人,产生不了真正的具身智能
编者按:
本文转载自“腾讯研究院”,多知经授权发布。腾讯首席科学家、腾讯Robotics X实验室主任张正友在“具身智能的一些挑战和进展”主题演讲中介绍了机器人的发展史及具身智能的挑战,还介绍了Robotics X实验室基于“层次化”控制来研发智能机器人的进展。张正友提到,和ChatGPT不同,具身智能是通过类人的感知方式(视觉、听觉、语言、触觉)来获取知识,并抽象成为一种表达语义来理解世界并作出行动,与世界交互。因此,大模型放到机器人上并不能马上能实现具身智能。
为深入探讨AI时代的人机关系,引领社会共同思考人机共生时代的经济发展机遇与社会应对策略,腾讯研究院联合前海国际事务研究院、青腾、香港科技园公司等机构举办 “AI时代的人机关系展望”论坛,这也是“人工智能+社会发展系列高端研讨会”的第二期。
论坛上,腾讯首席科学家、腾讯Robotics X实验室主任张正友在“具身智能的一些挑战和进展”主题演讲中,介绍了Robotics X实验室基于“层次化”控制来研发智能机器人的进展。“层次化”包括对本体、环境和任务共三层控制,层次化的具身智能的优势在于每个层次的知识都可以持续地更新和积累,而且层次之间能力可以解耦。腾讯Robotics X 实验室今年研发了自研的五指灵巧手和机械臂,移动底盘也首次融入到机器人身上,再加上感知大模型和规划大模型,能够让操作机器人实现自由对话和完成任务。
对于智能机器人将如何走进人们的生活,张正友说:“长远来看,机器人一定会走进千家万户,而在当下,机器人可能会在康复养老、个性化教育等领域首先带来巨大变化。”
以下为张正友的分享全文:
各位领导、各位嘉宾、各位老师、各位同学:大家下午好。我今天要跟大家分享关于具身智能的一些挑战和进展。
至于什么是具身智能,这个词去年突然火起来了,大家感觉很酷。其实,具身智能是相对于非具身智能而言的,像ChatGPT拥有的是没有身体的智能。对我来讲,具身智能体就是一个智能的机器人。至于这个智能是应该有身体还是没有身体的,对我们做机器人的来讲肯定是希望有身体,拥有身体才能把智能发育得更好。
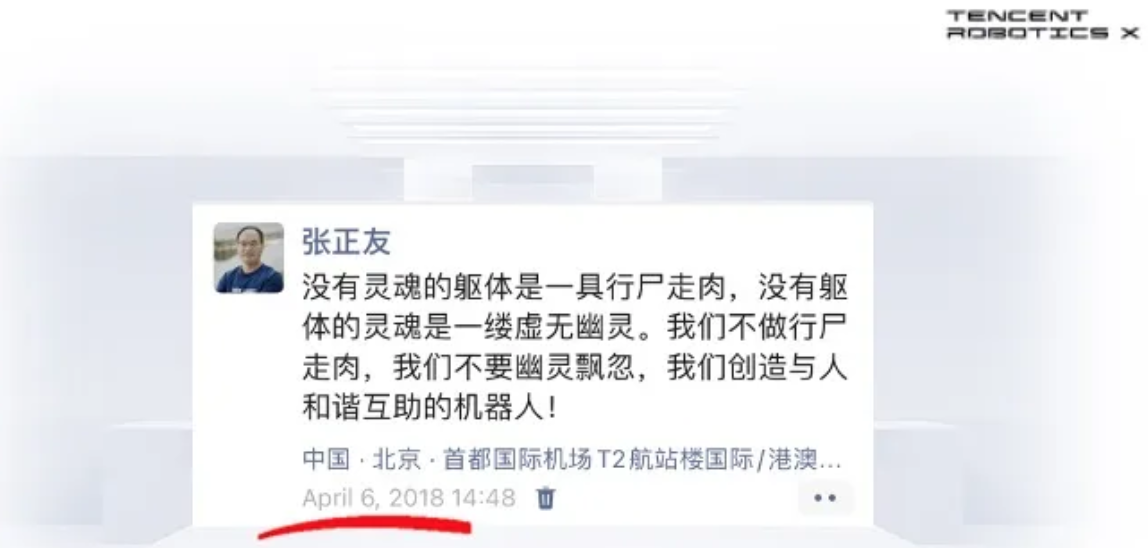
2018年年初,腾讯董事会主席兼首席执行官马化腾决定成立腾讯Robotics X,当时我还在朋友圈发了这样一段话(2018年4月6日朋友圈的内容):“没有灵魂的躯体是一具行尸走肉,没有躯体的灵魂是一缕虚无幽灵,我们不做行尸走肉,我们不要幽灵飘忽,我们创造与人和谐互助的机器人!”也就是我们要创建智能机器人来增强人的智力、发挥人类体能潜力、关怀人的情感、促进人和机器人的交互,迎接人和机器人共存、共创和共赢的时代,这是我们成立腾讯Robotics X的初衷。
其实,智能是否需要具身是有争议的,这个争议主要围绕认知科学展开。该领域内,大家认为许多认知特性是需要生物体的整体特性来塑造生物体的智能,但也有一部分人认为智能是不需要身体的,因为我们主要面临的是信息处理、问题解决和决策治理等任务,这些都可以通过软件和算法实现。具身智能这个词和概念很早就存在了,对很多人来讲,身体对于智能来说是至关重要的,因为智能源于生物体与其环境之间的交互,两者之间的互动有利于智能的发育和发展。

回过头看,图灵在1950年写的探讨如何实现机器智能的文章。可以看到,有一部分人认为可以用一些非常抽象的Activity,比方说下棋来实现(智能),还有一部分人认为,机器最好要有一些Organ(器官),比如speaker(话筒)来帮助我们更快的实现机器智能。不过,图灵自己也说不知道哪一类最好。Open AI最早的时候也买了上百台的机械臂,直接希望用机器人来实现AGI,经过一年多的努力发现这条道路暂时走不通,所以他们就放弃了,把精力聚焦在基于文本的大模型,最后成功开发出了ChatGPT。
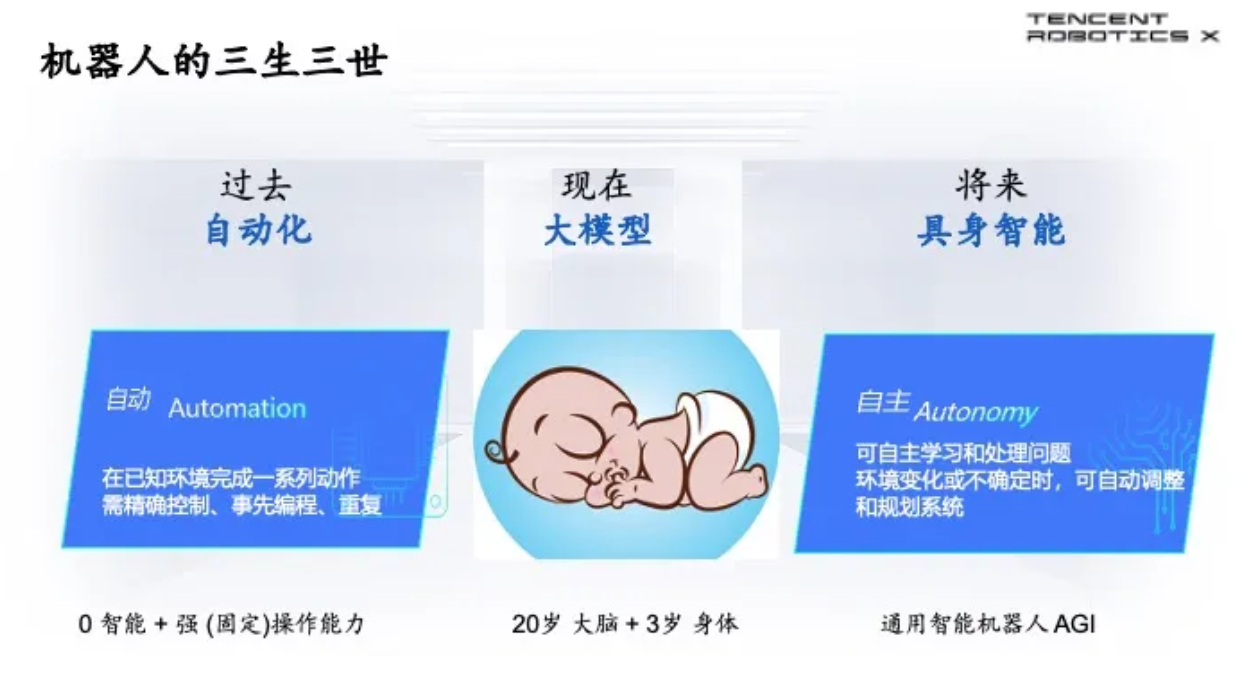
机器人有很悠久的历史,最初是生产线上机械臂的自动化,也就是在已知环境中完成一系列的动作,需要精确控制,我把它叫做零智能,是因为这个过程是不需要任何智能的。这一类的机器人虽然操作能力非常强,但是这些操作能力是为了一个固定环境预编程好的,是零智能。
进入大模型时代,也有人认为,大模型很厉害,放到机器人上马上就能够实现,实际上不是的。现在处于什么情况呢?打个比喻,就是相当于20岁大脑放在3岁的身体上,机器人虽然拥有一定的移动能力,但是操作能力非常弱。真正的具身智能要能够自主学习和处理问题,对环境变化和不确定的时候能够自动调整和规划,这是我们认为具身智能能够通往AGI或者是打造通用智能机器人非常重要的过程。
具体看来,具身智能是有物理载体的智能体(智能机器人)在一系列的交互中,通过感知、控制和自主学习来积累知识和技能,形成智能并影响物理世界的能力。这和ChatGPT是不太一样的,具身智能是通过类人的感知方式(视觉、听觉、语言、触觉)来获取知识,并抽象成为一种表达语义来理解世界并作出行动,与世界交互。这里面涉及到多个学科的融合,包括机械工程自动化、嵌入系统控制优化、认知科学、神经科学之类的,它是所有领域发展到一定程度以后能够涌现出来的一种能力。
具身智能面临着非常多的挑战:
首先是复杂的感知能力,包括视觉、听觉,现在大模型里包括GPT-4o也只是包括了视觉和听觉,还没有触觉。对具身智能来讲,触觉非常重要。机器人需要有复杂的感知能力,才能感知和理解周围不可预测的非结构化的环境和物体。
第二是强大的执行能力,包括移动、抓取、操纵以便能够与环境和物体进行交互。
第三是学习能力,能够从经验和数据中学习和适应,以便更好理解和应对环境的变化。
第四是自适应能力,能够自主调整自己的行为和策略,以便更好地应对不同的环境和任务。
第五是非常重要的,并不是把这些能力叠加就已经达到具身智能,而是要把这些能力有机、高效地协作融合才能真正地达到我们讲的希望的具身智能。
第六,在这个过程中,我们需要的数据是非常稀缺的,OpenAI最初是希望直接通过机器人达到AGI,由于数据的缺乏后面放弃了,但是数据还是需要解决的,数据的稀缺性是很大的挑战。在实际场景中收集数据时还需要保护用户的隐私安全。
第七因为具身智能是要生活在人类的人居环境,要保证自身和周围的安全。
第八是社会伦理的问题,机器人和人交互时要遵循道德和法律的规范,保护人类的利益和尊严。
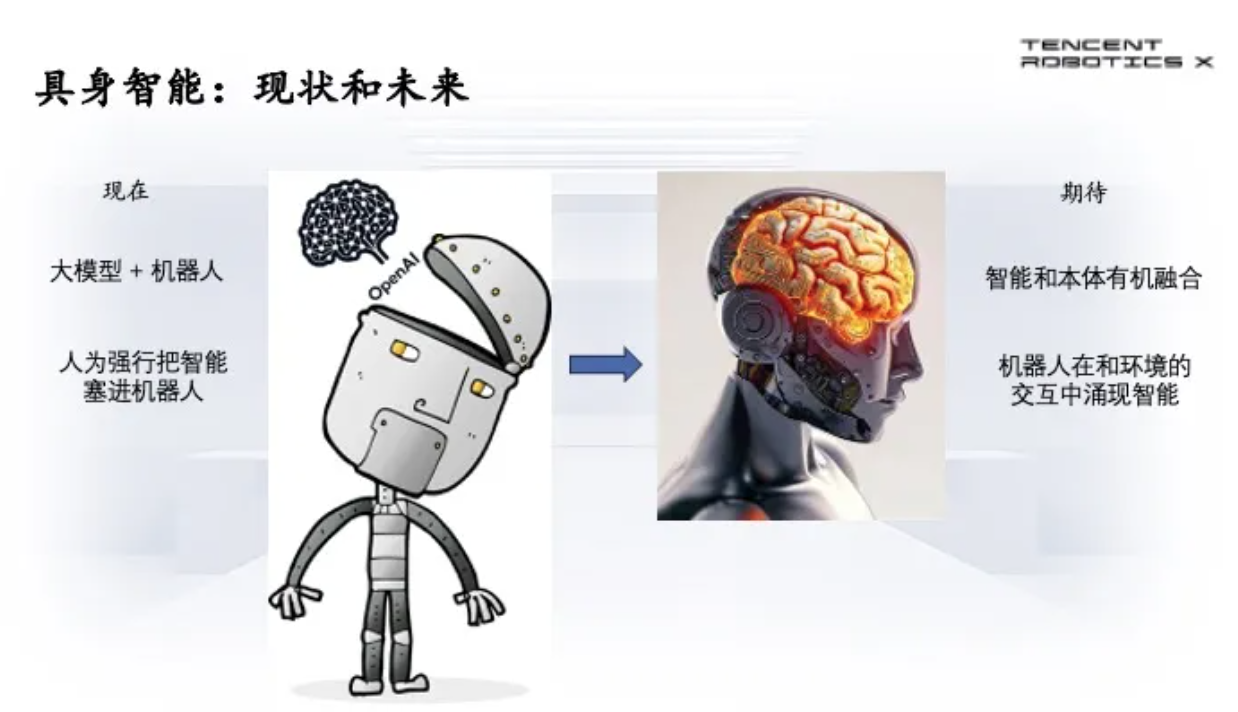
要达到具身智能是需要很多工作要做的,目前大家认为大模型可以解决智能机器人的问题,我这里画了一个图,相当于我们要把大模型塞到机器人的头里好像就解决了,但是这只是达到部分的智能。我们期待智能和本体要有机融合,这样机器人和环境交互中才能涌现出真正的智能。

为了达到这样的愿景,我认为需要改变控制范式。假如你们从机器人的教科书来看,传统的控制范式先是感知,感知之后是计划,计划之后是行动,行动之后再来感知这样的闭环过程,这个控制范式是不可能达到智能的。2018年我就提出了一个“SLAP范式”,S是感知,L是学习,A是行动,P是计划。感知和行动需要紧密相连,才能实时应对不断变化的环境。它们上面是规划,去解决复杂一点的任务。学习是渗透到各个模块,能够从经验和数据中学习,并能够自主调整自己的行为和策略。这个SLAP范式和人类的智能是有很相似的地方。
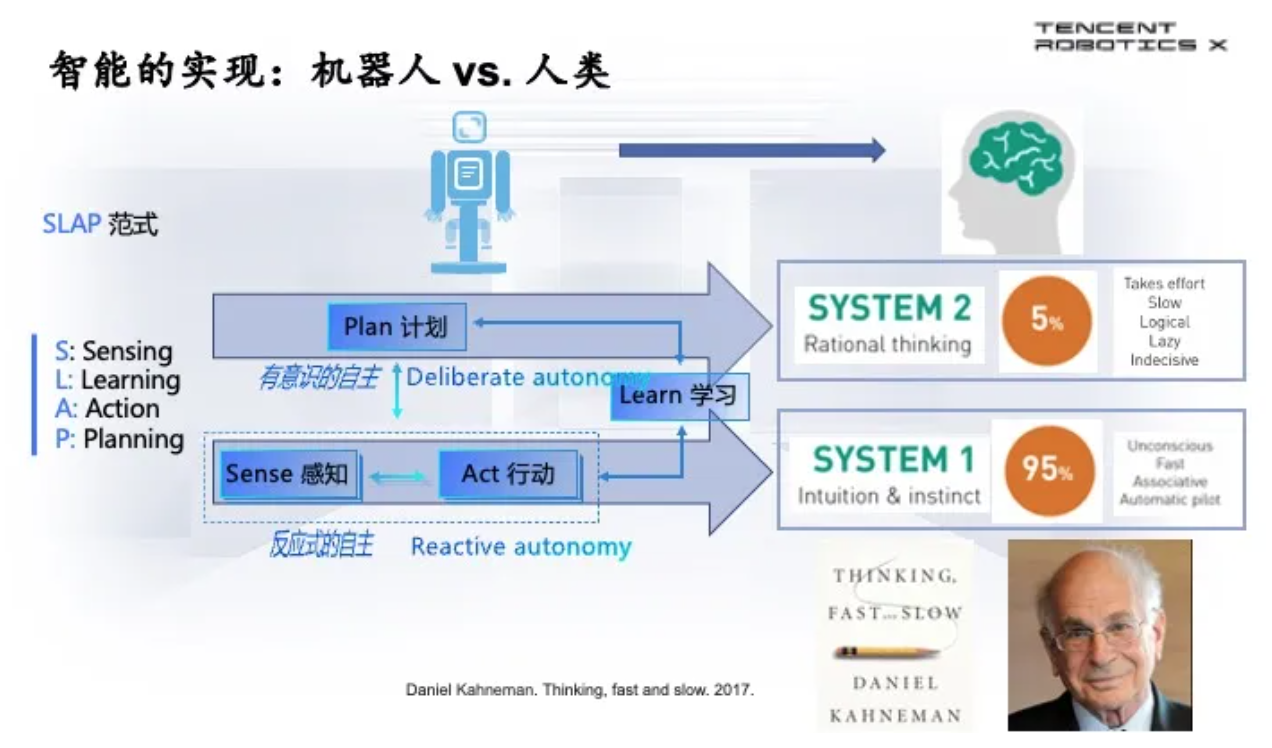
诺贝尔奖获得者Daniel Kahneman有一本书叫《Thinking,Fast and slow》,认为人脑是有两个系统的,第一个系统System 1是更多偏向于直觉,快速地解决问题。第二个系统是一种比较深度的思考,理性的思考,叫System 2。事实上,人95%的时间都在System 1,只有很少和复杂任务时才需要调度System 2,所以为什么人脑能够这么高效,只要几十瓦就能解决思考的问题,连一个GPU消耗的能量都不需要,这就是因为人类能够在95%的问题在System 1解决了,很难的任务才会到System 2。
我提出来的SLAP的范式,在底层,感知和行动之间紧密相连才能够解决反应式的自主,这就对应了System 1。有意识的自主是要达到System 2理性的思维和思考、
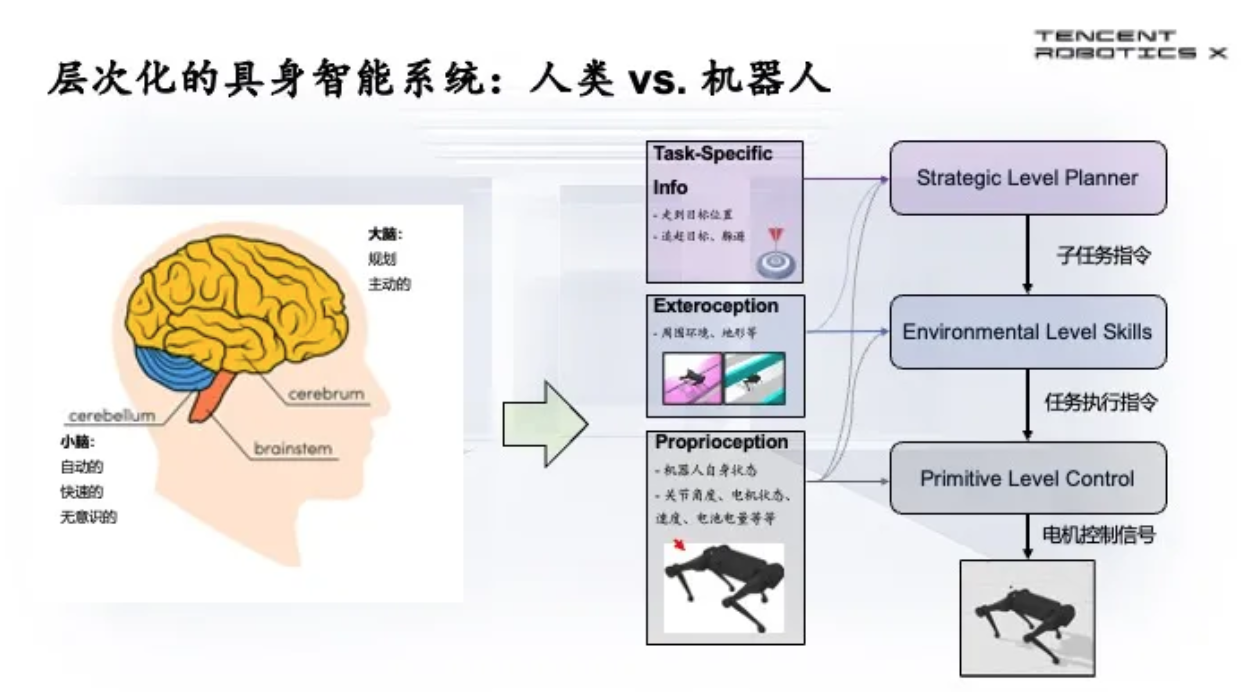
根据SLAP范式,结合人的大脑、以及小脑如何控制肢体的知识,我们研发了一个层次化的具身智能系统,分成了三层:最下面一层是Proprioception,就是机器人对自身的感知状况,这个地方对应到控制电机运动的电机信号。
第二层是Exteroception,也就是对环境的感知,通过环境的感知智能知道需要调用哪些能力完成这个任务。
最上面一层是和任务相关的叫做Strategic Level planner,针对特定任务,环境和机器人本体的能力做好规划才能把任务很好地解决。
下面就具体给大家做一些演示,最底层(Proprioception Level)的运动的控制也是从数据中进行学习的。这里让一个真狗在跑步机上不断地跑,同步做数据采集。通过模仿学习和强化学习,让机器人学会和真狗类似的运动。我们用了一个虚实集成世界,数字孪生、虚实统一。这里看到的只是狗的外表的运动方式,但到底机器人怎么动,需要多少力量,要发送的关节和电机的信号强度都是需要通过强化学习得到的。
另一段视频,在这里没有专门的人类控制,就是让机器狗学会了真狗的运动方式,它学会了之后就自己跑,有点活灵活现的感觉。
这是最基本的能力(运动能力),下一步是要对环境感知在环境里完成这些任务,刚才讲了在平地上动,第二步要把环境信息加进去,我们让它学会匍匐前进,怎样自然上台阶,怎么跨栏和怎么飞跃障碍物组合。
这时机器狗在仿真世界中已经学会了怎么跳跃、跨越障碍物。这只狗是我们自研的,叫Max,和一般的狗不太一样的地方是在膝盖上加了轮子,在平地上用轮子走得更快,不平的地方可以用四足,所以说是不同的模态组合。
当我们有了对环境适应能力之后就可以让它做各种不同的事情,比如我们要求其中一只狗追上另外一只狗,追上之后就赢了。为了增加复杂性,假如一个旗出现,原本逃的那只狗碰到这个旗之后就可以变成追了。大家可以看一下,这也是通过强化学习自动学会的。一只狗在追另外一只狗,当然我们把速度限制住了让狗跑得比较慢一点。现在变成了逃的那只狗去追,那只追的狗变了之后就转了一个弯骗了另一只狗一下。
这样一个层次化的具身智能的好处是每个层次的知识都可以持续地更新和积累,而且层次之间能力是可以解耦了,更新其他层级不会影响其他已有层级的知识。
比如说刚才从一只狗追另一只狗的时候,在强化学习时只学会了在平地上训练,根本没有加上障碍物,现在加了障碍物之后不需要重新学习,它自动学会了,因为在底层的时候知道怎么处理障碍物。大家可以看一下视频,这是我们根本没有重新训练的,上面加了障碍物,碰到一根棍子,他就钻过去,碰到障碍物就跳过去,这是自动(学习)的。
这些工作是去年年初就完成了,近期也会在国际顶级的学术期刊Nature Machine Intelligence上发表,并且作为封面故事,说明大家认为这样一个工作现在还是领先的。
下面讲一下我们过去一年在大模型融合方面进展,也就是将语言大模型以及多模态的感知大模型融合进我们的层次化具身智能系统。比如人给机器人派了一个煎蛋任务,基于LLM的规划大模型将煎蛋这个任务分解一下,就是要先把蛋从冰箱里拿出来,把蛋打在锅里面,然后要煎蛋。从多模态感知中,首先要知道这个蛋是放在冰箱里,需要调用下面的中层技能,机器人要先去冰箱把蛋拿出来,把冰箱门打开,抓握鸡蛋回到灶台。最下面就是底层控制的,控制机器人怎么到冰箱哪里,怎么打开冰箱门,等等,一旦学会都是自动完成的。最后是回到最顶层的Strategic Level Planner。注意在这个闭环里,机器人的行动作用于一个数字世界和物理世界紧密结合的虚实集成世界,在数字仿真空间里有机器人、也有看起来非常真实的场景,这样机器人的技能在虚拟空间学会之后可以直接应用到真实的空间里。
这里看一个视频。我们把一个智能机器人放在一个从来没见过的环境里面,第一步机器人要转一圈探索这个世界。比如视频里,机器人的任务是要把垃圾送到垃圾桶里,那么它首先要找到垃圾桶,找到垃圾桶之后就放过去了。同样把垃圾桶换一个地方,假设他不知道这个环境,通过探索发现了垃圾桶之后就把垃圾送过去了。
下面这个场景是要把鼠标送给蓝衣服和牛仔裤的人,这里面有很多其他人,他一定要找到穿蓝色衣服和牛仔裤的,他就自动去探索和找。这中间碰到的很多人不是蓝衣服不是牛仔裤,一直到机器人看到蓝衣服和牛仔裤,就把鼠标送到了。
在探索过程中,机器人能把周围的环境情况都记住了,不需要每次都重新探索。下面这个场景先是把药送给一个同事,这个感冒药的袋子再让机器人扔掉,它在探索建模时已经知道垃圾桶在什么地方,就直接去垃圾桶那边了。还可以利用空间的关系,比如说凳子在哪里、白板在哪里,要把一个东西送到白板和高凳子之间的一个人那里,中间有障碍物能够自动避开。
去年我们还做了一个调酒的机器人,那时候是用了一个自研的三指手,底盘是固定的,大家可以看一下。
这个花式调酒也是先采集了一个真人做调酒,把他的轨迹学会了,再到机器人身上实现。手指上也有触觉传感器,现在要把棍子插到孔里面,光靠视觉的能力是不够的,精度不够,所以它要靠触觉的感知到底有没有插进去,如果没有插进去的话要往边上移一下,最后实现把棍子插进去。
这是去年的工作,今年的工作有自研的五指手,机械臂也是我们自研的,去年没有自研的机械臂,现在也有移动底盘,加上感知大模型和规划大模型,能够实现操作机器人能够自由对话和完成任务。
右下角是从移动智能机器人看到的东西,在桌子上发现有一瓶whisky的酒,让它倒一杯whisky的酒,这是从机器人的视野里看到的,而且能够实时识别到各种各样的东西。
现在就分享到这里。谢谢大家。