对于教育应用场景来说,迎来更好的机会。

字节、阿里、百度开打大模型价格战,应用端即将崛起!
多知5月21日消息,继上周字节跳动的大模型喊出比行业便宜99.3%之后,今天阿里云也宣布大模型降价了,紧跟着,百度智能云宣布文心大模型两大主力模型全面免费,立即生效。
5月15日上午,字节跳动旗下云服务平台火山引擎总裁谭待在发布会上正式宣布,字节跳动自研豆包大模型对外提供服务。
谭待称,经过一年时间的迭代和市场验证,豆包大模型正成为国内使用量最大、应用场景最丰富的大模型之一,目前日均处理1200亿Tokens文本,生成3000万张图片。
根据在发布会披露数据,豆包用户规模在快速增长,月活用户数已达2600万,被创建智能体达800多万个。
在定价方面,字节是第一家降价的大厂,谭待在发布会上宣布,豆包通用模型pro-32k版模型推理输入价格仅为0.0008元/千Tokens,比行业低99.3%。

一元钱就能买到豆包主力模型的125万Tokens,大约是200万个汉字,豆包称,200万个汉字相当于3本《三国演义》。
紧跟着,5月21日,阿里云宣布,通义千问GPT-4级主力模型Qwen-Long,API(应用程序编程接口)输入价格从0.02元/千tokens降至0.0005元/千tokens,降价幅度高达97%。
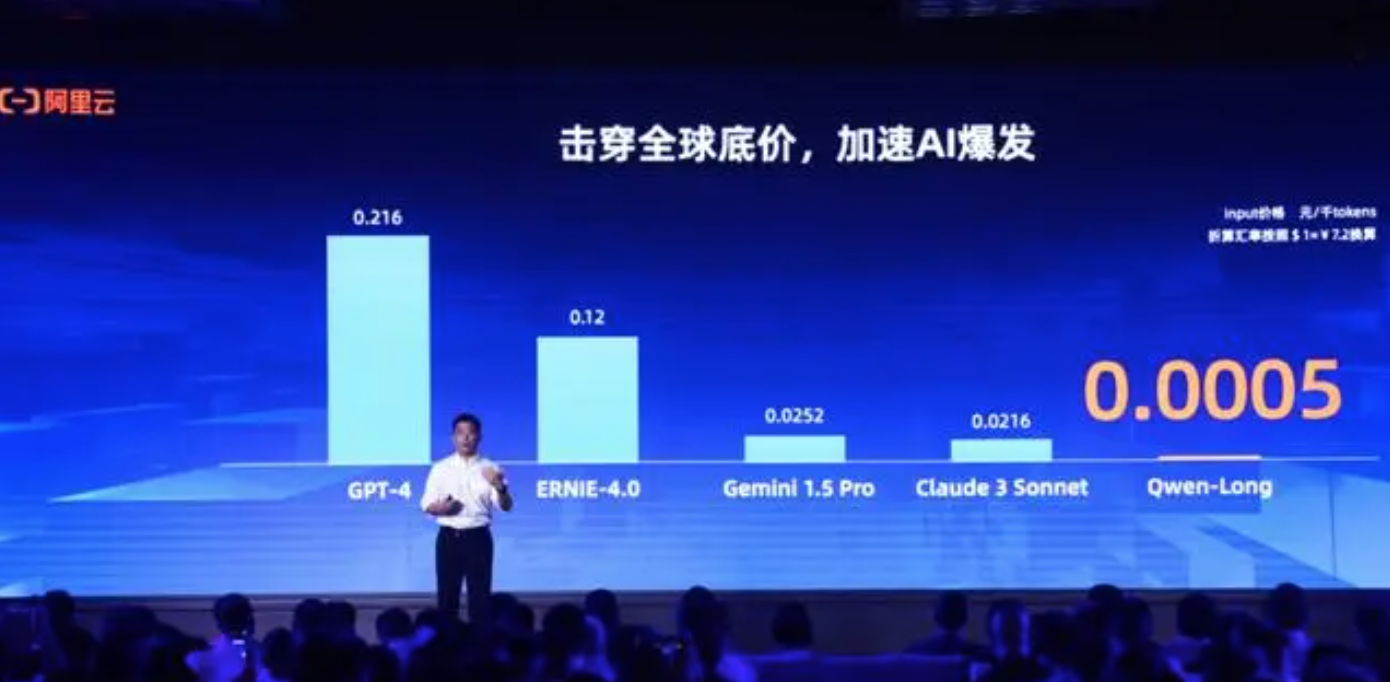
这意味着,1元钱可以买200万tokens。阿里云称,200万个汉字相当于5本《新华字典》的文字量。这款模型最高支持1千万tokens长文本输入。
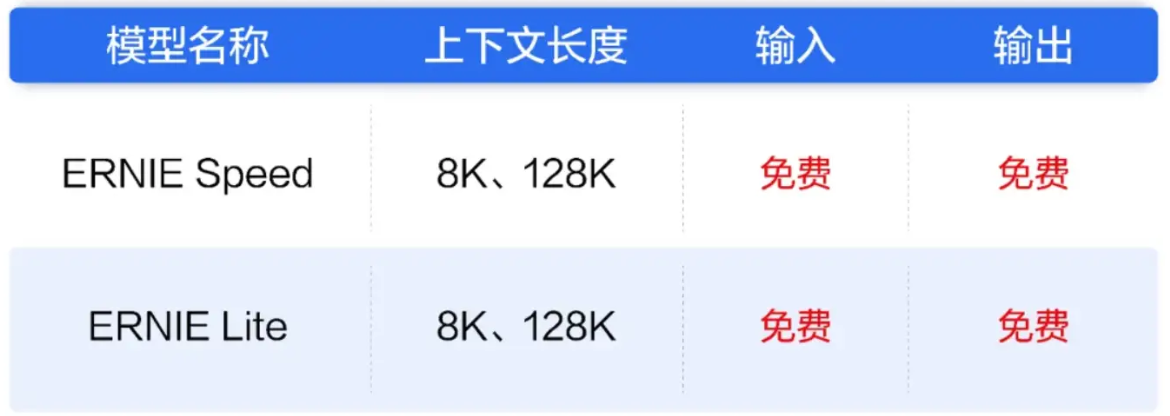
而百度智能云直接在官方账号宣布,文心大模型两大主力模型ENIRESpeed、ENIRELite将全面免费全面免费,上下文长度为8K、128K。
值得注意的是, 百度 文心大模型系列包括:旗舰版的ERNIE3.5和4.0,和轻量版的ERNIE Speed、Lite、Tiny等。也就是说,百度宣布免费的是小尺寸的模型ENIRESpeed和ENIRELite。
具体来看,ERNIE Speed是百度在2024年发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,同时具备极佳的推理性能;ERNIE Lite则是百度自研的轻量级大语言模型,兼顾优异的模型效果与推理性能,适合低算力 AI 加速卡推理使用。
但小尺寸的模型可能对于不少创业公司已经够用。百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上曾解释: “小模型推理成本低,响应速度快,在一些特定场景中,经过SFT(监督)精调后的小模型,它的使用效果可以媲美大模型。这就是我们发布ERNIE Speed、Lite、Tiny三个轻量模型的原因。”
不但是大厂降价了, 最近,大模型初创公司智谱AI将旗下入门级大模型GLM-3-Turbo(128K上下文)的价格从0.005元/千tokens降低到0.001元/千tokens,降幅达80%。私募巨头幻方量化旗下的大模型DeepSeek-V2(32K上下文)价格降至每千tokens输入0.001元、输出0.002元。
对比国外,国外厂商GPT-4、Gemini1.5 Pro及Claude 3 Sonnet每千tokens输入价格分别为0.22元、0.025元及0.022元,均远高于国内的价格。
可以看到,大厂们让大模型价格“卷”起来了,预示着大模型的商业化更进一步,但也让一些直接研发大模型的创业公司面临更残酷的竞争,同时,也预示着应用端即将崛起。
有“教育+AI Agent”项目创始人向多知提到:“对于我们这些初创公司而言,在调用大模型的时候非常注重价格,价格低的产品对我们更有吸引力。尤其是AI Agent,需要调用不同的大模型。”
不过也有业内人士提到:“大模型的应用,不仅要看价格,还要看应用效果和响应速度。”
不论如何,对于教育应用场景来说,迎来更好的机会,未来将有更多大模型应用落地。(多知 王上)